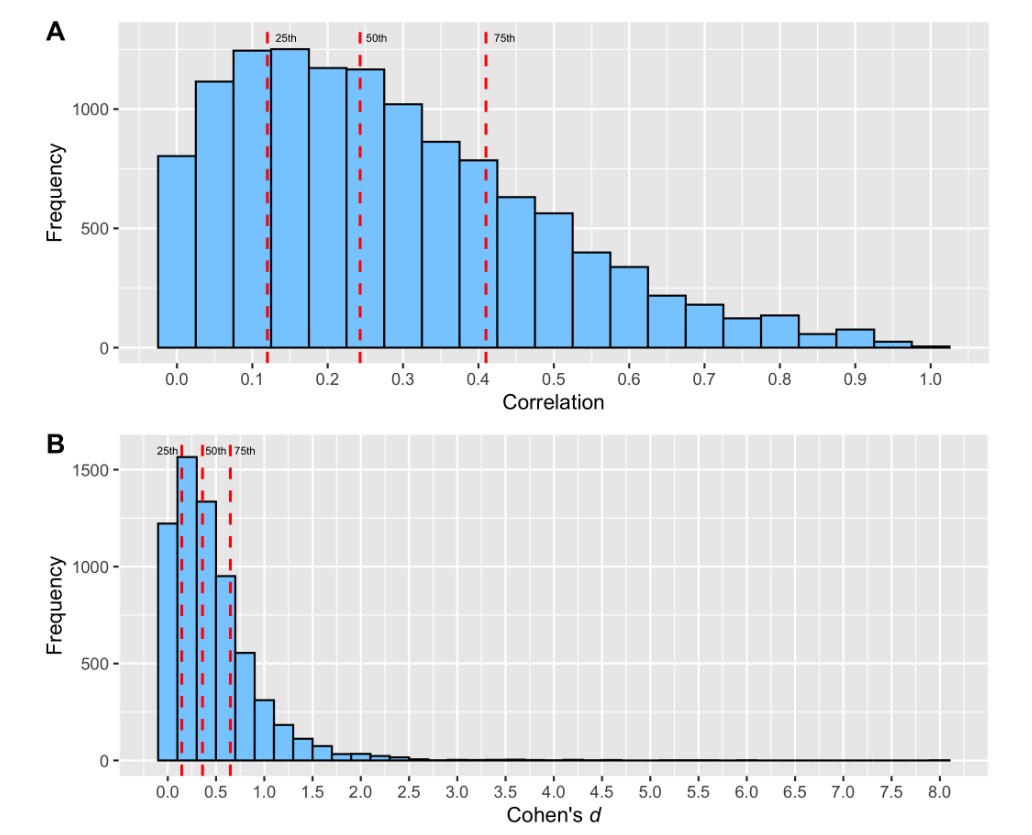
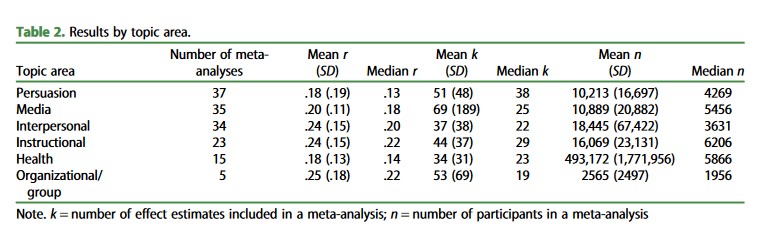
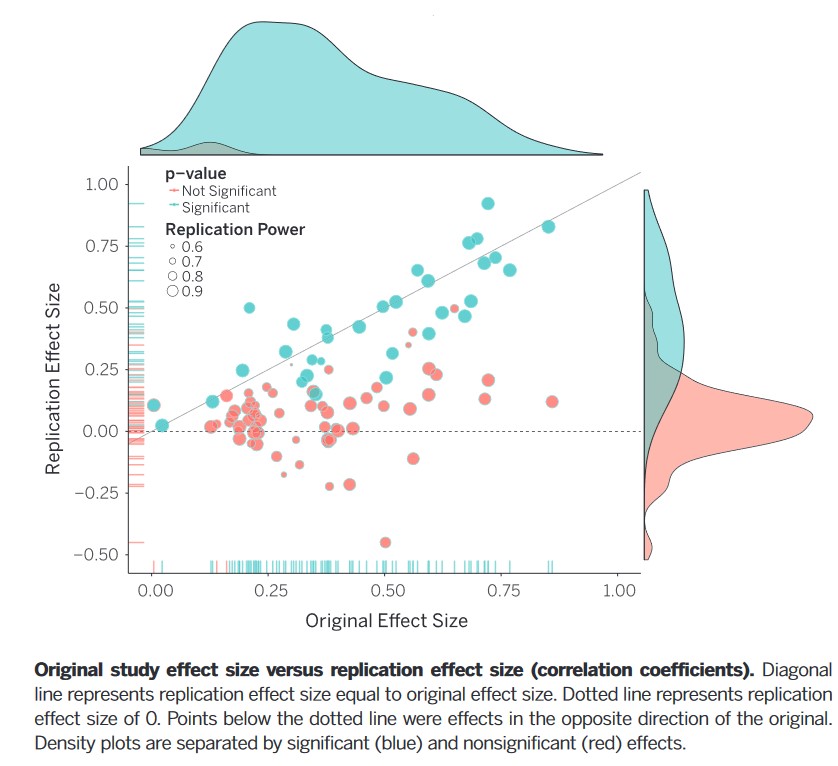
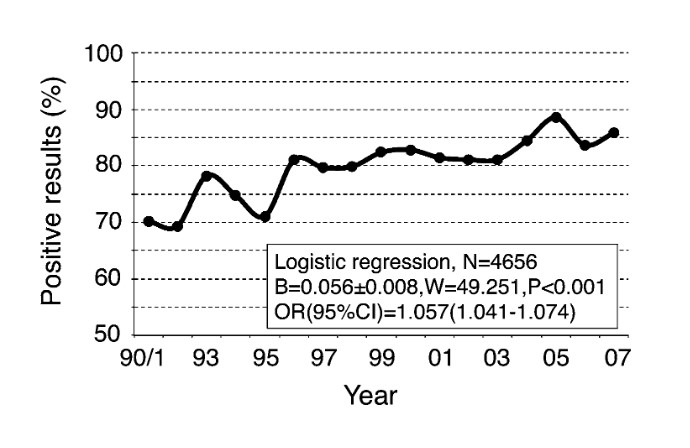
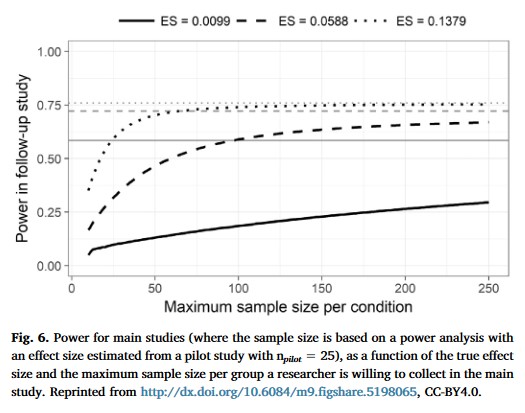
Albers, Casper J., and Daniël Lakens. 2018.
“When Power Analyses Based on Pilot Data Are Biased: Inaccurate Effect Size Estimators and Follow-up Bias.” Journal of Experimental Social Psychology 74: 187–95.
https://doi.org/10.17605/OSF.IO/B7Z4Q.
Anvari, Farid, Rogier Kievit, Daniel Lakens, Andrew K. Przybylski, Leo Tiokhin, Brenton M. Wiernik, and Amy Orben. 2021.
“Evaluating the Practical Relevance of Observed Effect Sizes in Psychological Research,” June.
https://doi.org/10.31234/osf.io/g3vtr.
Anvari, Farid, and Daniël Lakens. 2021.
“Using Anchor-Based Methods to Determine the Smallest Effect Size of Interest.” Journal of Experimental Social Psychology 96 (September): 104159.
https://doi.org/10.1016/j.jesp.2021.104159.
Baguley, Thom. 2009.
“Standardized or Simple Effect Size: What Should Be Reported?” British Journal of Psychology 100 (3): 603–17.
https://doi.org/10.1348/000712608X377117.
Cohen, J. 1988. Statistical Power Analysis for the Behavioral Sciences. 2nd ed. Hillsdale, NJ: Lawrence Erlbaum.
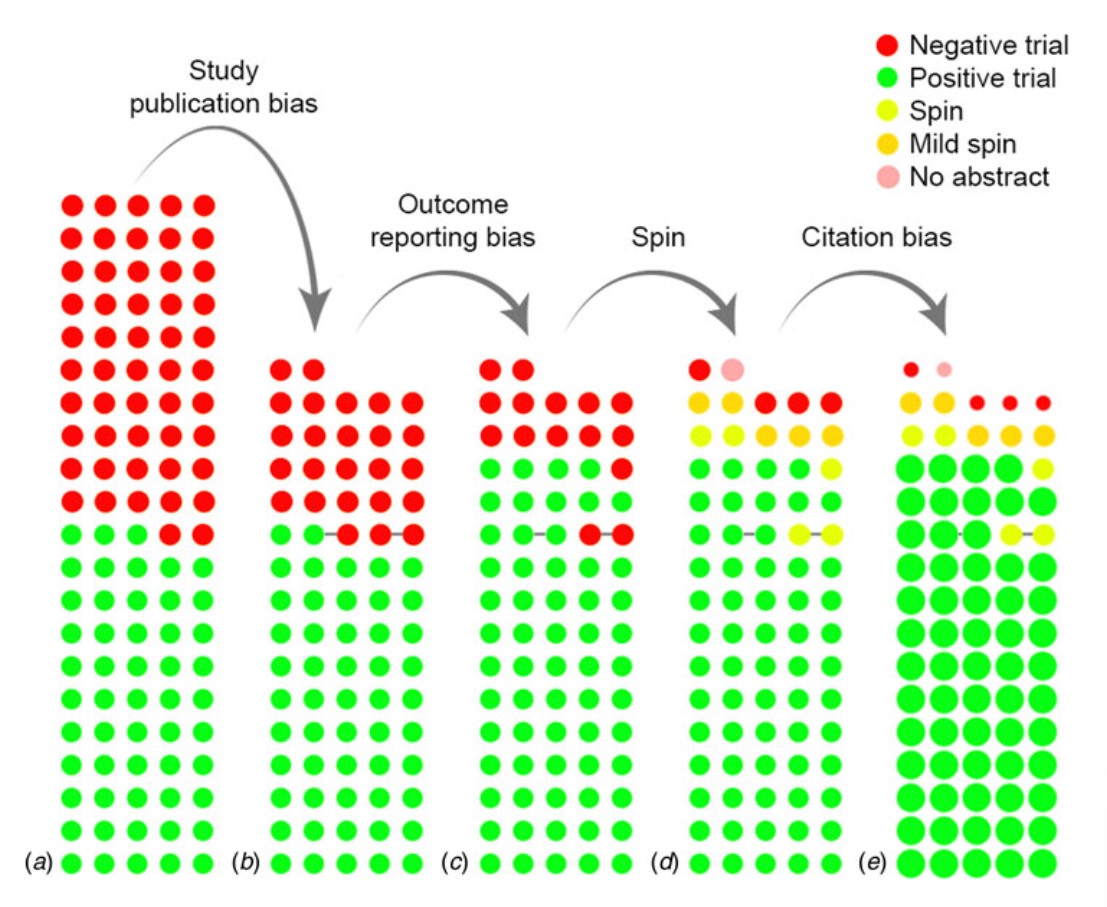
De Vries, Y. A., A. M. Roest, Peter de Jonge, Pim Cuijpers, M. R. Munafò, and J. A. Bastiaansen. 2018. “The Cumulative Effect of Reporting and Citation Biases on the Apparent Efficacy of Treatments: The Case of Depression.” Psychological Medicine 48 (15): 24532455.
Fanelli, Daniele. 2012.
“Negative Results Are Disappearing from Most Disciplines and Countries.” Scientometrics 90 (3): 891–904.
https://doi.org/10.1007/s11192-011-0494-7.
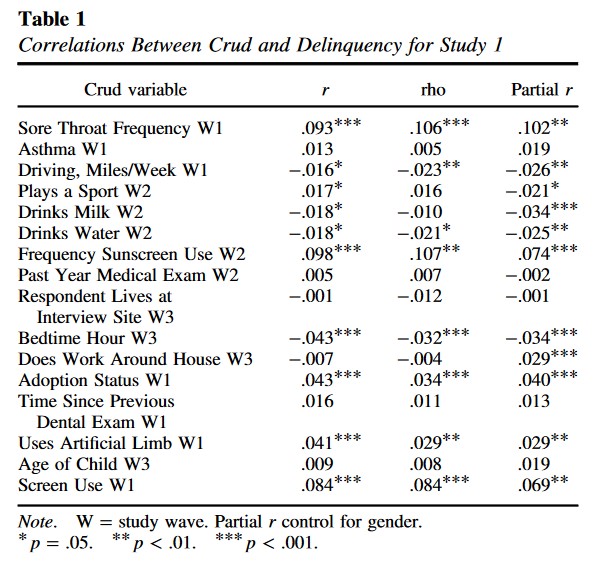
Ferguson, Christopher J., and Moritz Heene. 2021.
“Providing a Lower-Bound Estimate for Psychology’s “Crud Factor”: The Case of Aggression.” Professional Psychology: Research and Practice 52 (6): 620–26.
https://doi.org/10.1037/pro0000386.
Fisher, Ronald A. 1926. “The Arrangement of Field Experiments.” Journal of the Ministry of Agriculture 33: 503–15.
Funder, David C., and Daniel J. Ozer. 2019.
“Evaluating Effect Size in Psychological Research: Sense and Nonsense.” Advances in Methods and Practices in Psychological Science 2 (2): 156–68.
https://doi.org/10.1177/2515245919847202.
Gignac, Gilles E., and Eva T. Szodorai. 2016.
“Effect Size Guidelines for Individual Differences Researchers.” Personality and Individual Differences 102 (November): 74–78.
https://doi.org/10.1016/j.paid.2016.06.069.
Hilgard, Joseph. 2021.
“Maximal Positive Controls: A Method for Estimating the Largest Plausible Effect Size.” Journal of Experimental Social Psychology 93 (March): 104082.
https://doi.org/10.1016/j.jesp.2020.104082.
Hill, Carolyn J., Howard S. Bloom, Alison Rebeck Black, and Mark W. Lipsey. 2008.
“Empirical Benchmarks for Interpreting Effect Sizes in Research.” Child Development Perspectives 2 (3): 172–77.
https://doi.org/10.1111/j.1750-8606.2008.00061.x.
Lakens, Daniël. 2013.
“Calculating and Reporting Effect Sizes to Facilitate Cumulative Science: A Practical Primer for t-Tests and ANOVAs.” Frontiers in Psychology 4 (NOV): 1–12.
https://doi.org/10.3389/fpsyg.2013.00863.
Lantz, Björn. 2013.
“The Large Sample Size Fallacy.” Scandinavian Journal of Caring Sciences 27 (2): 487–92.
https://doi.org/10.1111/j.1471-6712.2012.01052.x.
Levine, Timothy R., and Craig R. Hullett. 2002.
“Eta Squared, Partial Eta Squared, and Misreporting of Effect Size in Communication Research.” Human Communication Research 28 (4): 612–25.
https://doi.org/10.1111/j.1468-2958.2002.tb00828.x.
Lovakov, Andrey, and Elena R. Agadullina. 2021.
“Empirically Derived Guidelines for Effect Size Interpretation in Social Psychology.” European Journal of Social Psychology 51 (3): 485–504.
https://doi.org/10.1002/ejsp.2752.
Meyer, Gregory J., Stephen E. Finn, Lorraine D. Eyde, Gary G. Kay, Kevin L. Moreland, Robert R. Dies, Elena J. Eisman, Tom W. Kubiszyn, and Geoffrey M. Reed. 2001. “Psychological Testing and Psychological Assessment: A Review of Evidence and Issues.” American Psychologist 56 (2): 128.
Open Science Collaboration. 2015.
“Estimating the Reproducibility of Psychological Science.” Science 349 (6251): aac4716–16.
https://doi.org/10.1126/science.aac4716.
Orben, Amy, and Daniel Lakens. 2019.
“Crud (Re)defined,” May.
https://doi.org/10.31234/osf.io/96dpy.
Rains, Stephen A., Timothy R. Levine, and Rene Weber. 2018.
“Sixty Years of Quantitative Communication Research Summarized: Lessons from 149 Meta-Analyses.” Annals of the International Communication Association 8985: 1–20.
https://doi.org/10.1080/23808985.2018.1446350.
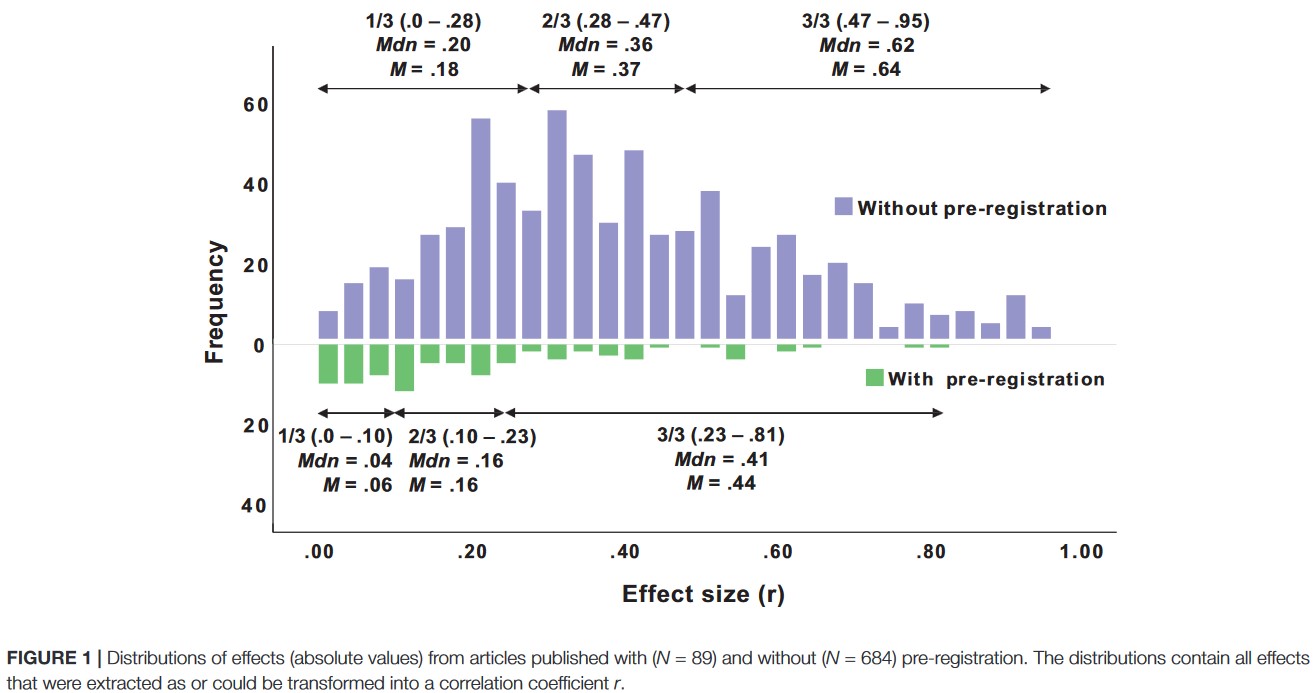
Schäfer, Thomas, and Marcus A. Schwarz. 2019.
“The Meaningfulness of Effect Sizes in Psychological Research: Differences Between Sub-Disciplines and the Impact of Potential Biases.” Frontiers in Psychology 10.
https://doi.org/10.3389/fpsyg.2019.00813.
Szucs, Denes, and John P. A. Ioannidis. 2017.
“Empirical Assessment of Published Effect Sizes and Power in the Recent Cognitive Neuroscience and Psychology Literature.” PLoS Biology 15 (3).
https://doi.org/10.1371/journal.pbio.2000797.