Call:
lm(formula = disagreeableness ~ age)
Residuals:
Min 1Q Median 3Q Max
-1.287e-13 3.740e-16 9.290e-16 1.765e-15 1.018e-14
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -2.274e-14 3.426e-15 -6.637e+00 1.78e-09 ***
age 1.000e+00 6.370e-17 1.570e+16 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.323e-14 on 98 degrees of freedom
Multiple R-squared: 1, Adjusted R-squared: 1
F-statistic: 2.465e+32 on 1 and 98 DF, p-value: < 2.2e-16Continuous predictors
Power analysis through simulation in R
Niklas Johannes
Takeaways
- Understand that continuous predictors are just another case of the linear model
- Extend this understanding to continuous (by categorical) interactions
- Be able to translate that extension to generating data
Back to the linear model
So far our predictors have been categorical. If we have two groups predicting an outcome and our predictor is 0:
\[\begin{align} & y = \beta_0 + \beta_1x\\ & y = \beta_0 + \beta_1 \times 0\\ & y = \beta_0 \end{align}\]If it’s 1:
\[\begin{align} & y = \beta_0 + \beta_1x\\ & y = \beta_0 + \beta_1 \times 1\\ & y = \beta_0 + \beta_1 \end{align}\]Changing \(x\)
A continuous predictor is nothing new: We’re basically looking at what happens if \(x\) goes up by 1. So if our measure isn’t categorical (aka dummy coded), but continuous, we’re asking the same question. Only now, \(x\) can be more than 0 or 1.
\[\begin{align} y &= \beta_0 + \beta_1x \\ y &= \beta_0 + \beta_11 \\ y &= \beta_0 + \beta_12 \\ y &= \beta_0 + \beta_13 \\ y &= \dots \end{align}\]Full range of \(x\)
If we assume linearity, then getting \(y\) is easy. Assume we predict disagreeableness from age. With each year people grow older, they become 1 point more disagreeable on a 100-point scale. (And when they’re 0 years old, they’re also 0 disagreeable.)
\[\begin{align} & disagreeableness = \beta_0 + \beta_1 \times age\\ & disagreeableness = 0 + 1 \times age \end{align}\]Now getting the score for someone aged 50 is trivial:
\(disagreeableness = 0 + 1 \times 50\)
Simulating this process is easy
We get our age, put it into the formula, and we have our outcome.
Perfect fit
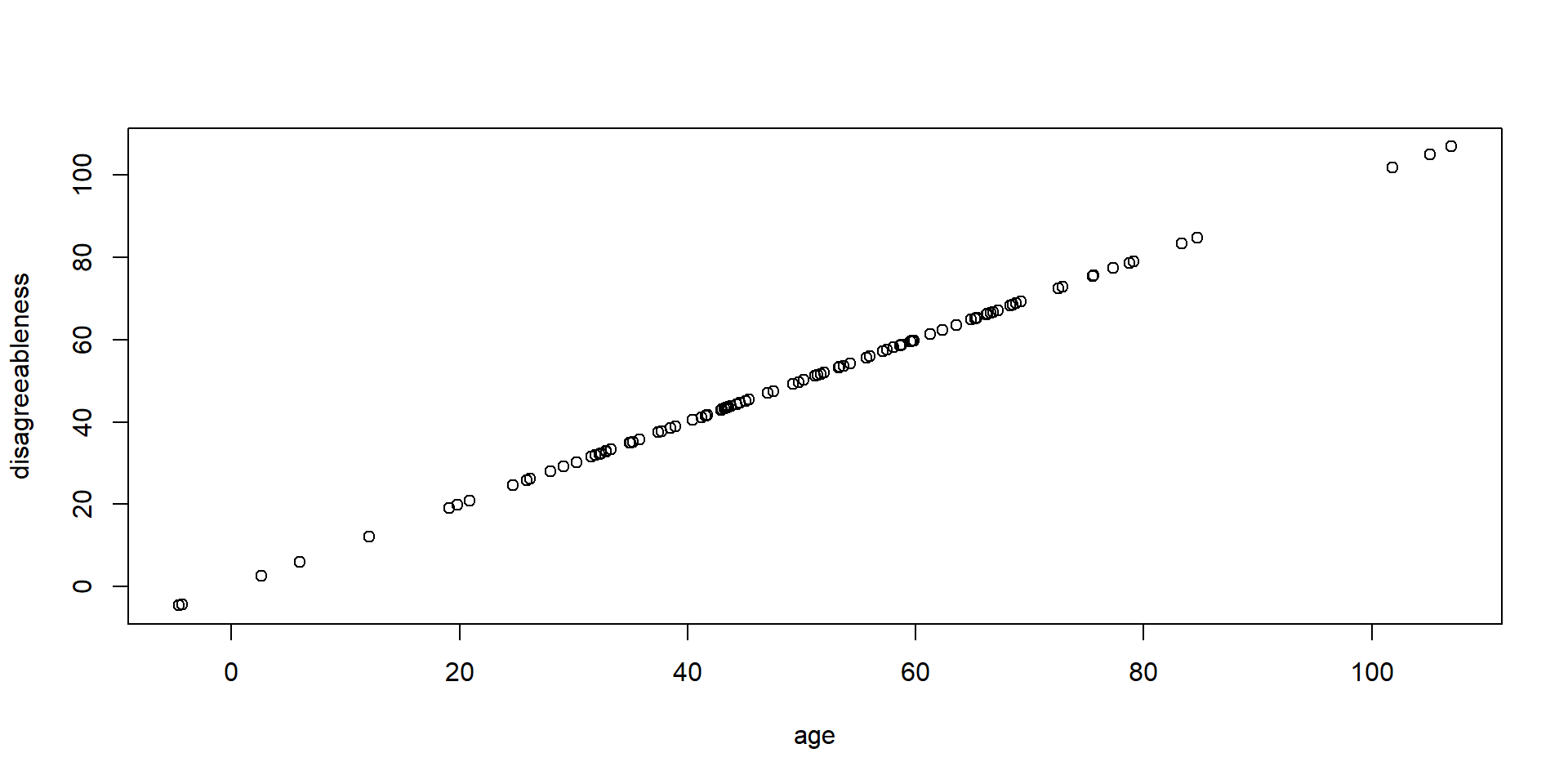
Adding error
If there’s lots of error, it’ll be harder to separate signal (aka our true 1-point effect) from noise (the additional variation in our outcome).
Call:
lm(formula = disagreeableness ~ age)
Residuals:
Min 1Q Median 3Q Max
-182.39 -65.60 -12.45 61.45 300.97
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.5999 25.4154 -0.024 0.9812
age 1.1264 0.4725 2.384 0.0191 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 98.13 on 98 degrees of freedom
Multiple R-squared: 0.05481, Adjusted R-squared: 0.04517
F-statistic: 5.683 on 1 and 98 DF, p-value: 0.01906Psst, scale
Adding this much error will bring our outcome measure out of bounds. For a proper simulation where we’re interested in the data generating process, we need to deal with this (by truncating etc.).
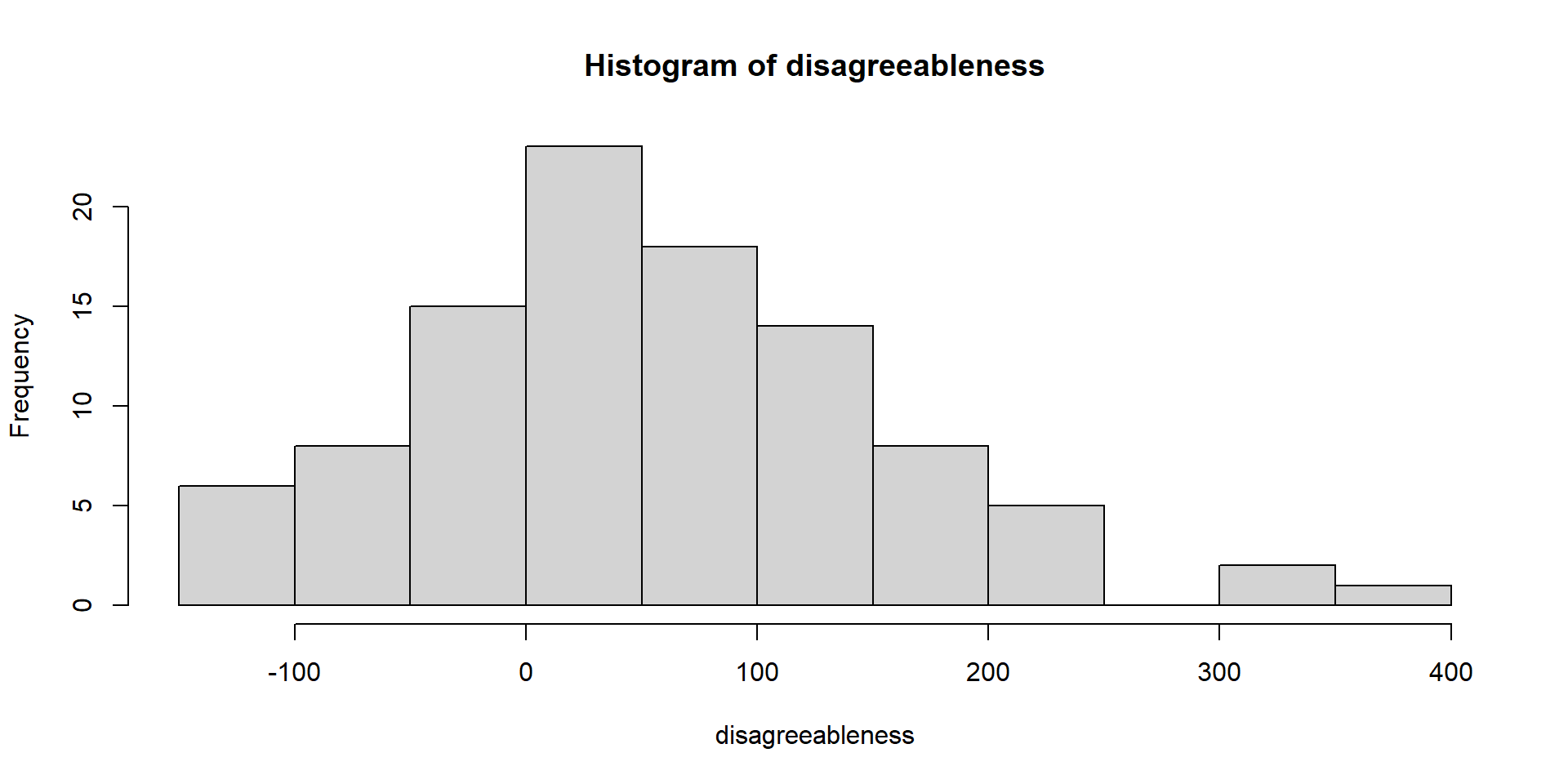
That’s it, really
For the linear model, it doesn’t matter on what level our predictor is. Categorical or continuous, we can simulate any outcome with this formula—including multiple predictors and interactions between different levels of predictors.
Let’s assume number of relatives living close-by is also causing disagreeableness:
Two independent effects
Call:
lm(formula = disagreeableness ~ age + relatives)
Residuals:
Min 1Q Median 3Q Max
-27.018 -6.560 0.326 6.535 23.319
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -2.4204 3.2527 -0.744 0.4586
age 1.0096 0.0470 21.480 <2e-16 ***
relatives 1.1264 0.4591 2.453 0.0159 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 9.882 on 97 degrees of freedom
Multiple R-squared: 0.8301, Adjusted R-squared: 0.8266
F-statistic: 237 on 2 and 97 DF, p-value: < 2.2e-16A tangent
Causality is hard. Best to stay away from multiple predictors unless we’re prepared to defend our causal model.
When both the predictor and control variable are unreliable measures of the same construct, the true predictive effect of the construct gets partitioned into two coefficients, neither of which capture the full causal effect. (Wysocki, Lawson, and Rhemtulla 2022)
Varying effect sizes
What if we believe the effect of age is smaller, but that of number of relatives much larger. No problem, we just adjust our betas. Say each year only contributes 0.25 higher grumpiness, but each extra relative contributes 5 points on grumpiness.
\[\begin{align} & disagreeableness = \beta_0 + \beta_1 \times age + \beta_2relatives\\ & disagreeableness = 0 + 0.25 \times age + 5 \times relatives \end{align}\]In R
disagreeableness <- 0 + 0.25*age + 5*relatives + error
summary(lm(disagreeableness ~ age + relatives))
Call:
lm(formula = disagreeableness ~ age + relatives)
Residuals:
Min 1Q Median 3Q Max
-27.018 -6.560 0.326 6.535 23.319
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -2.4204 3.2527 -0.744 0.459
age 0.2596 0.0470 5.523 2.79e-07 ***
relatives 5.1264 0.4591 11.166 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 9.882 on 97 degrees of freedom
Multiple R-squared: 0.6252, Adjusted R-squared: 0.6175
F-statistic: 80.91 on 2 and 97 DF, p-value: < 2.2e-16That’s the data generating process
In our simulation, we yet again make our assumptions explicit about how the data are generated: According to this linear model and our inputs (aka numbers).
Error adds uncertainty to our data generating process. It specifies that our linear model doesn’t 100% explain the causal structures and that there are influences on our outcome that we haven’t accounted for (or that an effect is heterogeneous).
About that intercept
\(disagreeableness = \beta_0 + \beta_1 \times age + \beta_2relatives\)
Now the intercept is disagreeableness when both age and number of relatives are 0. Maybe 0 age doesn’t make a lot of sense, so let’s center that variable.
Now the meaning intercept changes: Disagreeableness at average age and 0 relatives living close-by. Easier to have an intuition for.
In R
The effect for age doesn’t change, but the interpretation of the intercept does: Now it’s the disagreeableness when there’s no relatives and age is at average.
centered_age <- scale(age, center = TRUE, scale = FALSE)
summary(lm(disagreeableness ~ centered_age + relatives))
Call:
lm(formula = disagreeableness ~ centered_age + relatives)
Residuals:
Min 1Q Median 3Q Max
-27.018 -6.560 0.326 6.535 23.319
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 10.7744 2.3192 4.646 1.07e-05 ***
centered_age 0.2596 0.0470 5.523 2.79e-07 ***
relatives 5.1264 0.4591 11.166 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 9.882 on 97 degrees of freedom
Multiple R-squared: 0.6252, Adjusted R-squared: 0.6175
F-statistic: 80.91 on 2 and 97 DF, p-value: < 2.2e-16Simulate power
n <- 100
effect <- 0.10
runs <- 1000
pvalues <- NULL
for (i in 1:runs) {
age <- rnorm(n, 50, 20)
centered_age <- scale(age, center = TRUE, scale = FALSE)
error <- rnorm(n, 0, 10)
disagreeableness <- 50 + effect*centered_age + error
disagreeableness <- ifelse(disagreeableness > 100, 100, disagreeableness)
disagreeableness <- ifelse(disagreeableness < 0, 0, disagreeableness)
m <- summary(lm(disagreeableness ~ centered_age))
pvalues[i] <- broom::glance(m)$p.value
}
sum(pvalues < 0.05) / length(pvalues)[1] 0.485Standardized effects?
What if we want to work with standardized effects? Remember that a standardized effect is just an expression of standard deviation units? So we can standardize our variables and voila: \(r\).
Let’s compare
[1] 0.4281227
Call:
lm(formula = stan_dis ~ stan_age)
Residuals:
Min 1Q Median 3Q Max
-2.3554 -0.5474 -0.1218 0.4755 2.5096
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.064e-17 9.083e-02 0.00 1
stan_age 4.281e-01 9.129e-02 4.69 8.86e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.9083 on 98 degrees of freedom
Multiple R-squared: 0.1833, Adjusted R-squared: 0.175
F-statistic: 21.99 on 1 and 98 DF, p-value: 8.86e-06Not super clean
This doesn’t give us a lot of control over the standardized effect size (our raw effect of 0.25 just happened to be 0.22 SDs). How about we just start off with standardized variables? If we want \(r\) = 0.20, we can do that as follows:
\(r\) = 0.20?
Call:
lm(formula = stan_dis ~ stan_age)
Residuals:
Min 1Q Median 3Q Max
-1.09330 -0.20679 0.00066 0.20381 1.02869
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.0005512 0.0030027 -0.184 0.854
stan_age 0.1957996 0.0029714 65.895 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.3003 on 9998 degrees of freedom
Multiple R-squared: 0.3028, Adjusted R-squared: 0.3027
F-statistic: 4342 on 1 and 9998 DF, p-value: < 2.2e-16Wait a second
Why isn’t the effect as we specified?
Because we didn’t standardize
We created the standardized version of disagreeableness with
That means the variable isn’t actually standardized:
How do we fix this?
Luckily, we encountered a way to simulate variables, including their means, standard deviations, and correlations: The variance-covariance matrix. Now, we just make sure the means are 0 and standard deviations are 1.
Correlation matrix
\[ \begin{bmatrix} var & cov \\ cov & var \\ \end{bmatrix} \]
\[ \begin{bmatrix} sd^2 & r\times sd \times sd \\ r\times sd \times sd & sd^2 \\ \end{bmatrix} \]
\[ \begin{bmatrix} 1^2 & 0.2\times 1 \times 1 \\ 0.2\times 1 \times 1 & 1^2 \\ \end{bmatrix} \]
\[ \begin{bmatrix} 1 & 0.2 \\ 0.2 & 1 \\ \end{bmatrix} \]
Let’s simulate that
What if we want both?
So now we know how to:
- Specify an outcome on the raw scale, but we sort of eyeball the error
- Specify both predictor and outcome on the standardized scale, full control over means, SDs, but we prefer unstandardized
How do we specify an effect on the raw scale, but use the multivariate normal distribution? Remember the formula for \(r\)?
\(r = B_{xy} \frac{\sigma_x}{\sigma_y}\)
Just plug in the number then
Say we want a raw effect of age on disagreeableness of 0.5 points. We want age to have a mean of 50 and an SD of 20. We want disagreeableness to have a mean of 60 and an SD of 15. Let’s use the raw score and SDs first.
Then we get the covariances
Now that we have our correlation, we can get the covariates and fill everything into our variance covariance matrix.
Get some data
Now all we need are some means, and we’re good to go.
Let’s check it all worked
Can we recover our raw effect of 0.5?
Call:
lm(formula = disagreeableness ~ age, data = d)
Residuals:
Min 1Q Median 3Q Max
-39.376 -7.649 -0.091 7.637 39.706
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 34.870513 0.299804 116.31 <2e-16 ***
age 0.502866 0.005571 90.27 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 11.2 on 9998 degrees of freedom
Multiple R-squared: 0.449, Adjusted R-squared: 0.449
F-statistic: 8148 on 1 and 9998 DF, p-value: < 2.2e-16Standardized effect size
\(r = B_{xy} \frac{\sigma_x}{\sigma_Y}\)
A word on getting that \(r\)
\(r = B_{xy} \frac{\sigma_x}{\sigma_Y}\)
What if we had specified an SD of 20 for age (\(x\)) and an SD of 5 for disagreeableness (\(y\))?
But \(r\) can’t be larger than 1–what’s going on??
Data generating process creates limits
When we determine the “raw” regression slope, we also determine the causal structure. In other words: If we say Y is caused by X, the SD of Y will be dependent on the SD of X and the effec size.
Perfect correlation: \(y\) is ten times the size of \(x\).
Maximum correlation
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-6.221e-11 -2.500e-14 -2.000e-15 2.000e-14 1.114e-10
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -5.093e-13 3.510e-14 -1.451e+01 <2e-16 ***
x 1.000e+01 6.523e-16 1.533e+16 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.276e-12 on 9998 degrees of freedom
Multiple R-squared: 1, Adjusted R-squared: 1
F-statistic: 2.35e+32 on 1 and 9998 DF, p-value: < 2.2e-16Maximum correlation
Now if we use the formula, we can get the maximum correlation of 1 because the outcome SD is exactly 10 times the predictor SD, which is exactly our effect:
Let’s add some error
Now our correlation is lower
Bottom line
If you’re saying that one variable is caused by another, you’re not free to choose the variation of the outcome variable. The variation is a result of the data generating process and you’re determining what the data generating process is with your linear model. For our example, with a raw effect of 10, the smallest SD we can choose for the outcome is 10 times that of the cause.
Back to our example: If age causes disagreeableness with an effect of 0.5, then the SD of disagreeableness can only be as small as half the SD of age.
Bottom line
In other words, by determining the effect size and SD of the cause, you’re setting bounds on the range and SD of the outcome. You need to take that into account when simulating data: What’s a sensible raw effect size in relation to both the scale of the cause and the effect?
Likert setup
Let’s say both predictor and outcome are on a 7-point Likert-scale. You think that both should be roughly on the mid-point with a 1.2-point SD for predictor and 0.9 for outcome. As a raw effect, you assume 0.3 points as your SESOI. Do those SDs make sense? Would they produce a sensible \(r\)?
Power
means <- c(x = 4, y = 4)
sd_x <- 1.2
sd_y <- 0.9
sesoi <- 0.3
r <- sesoi * sd_x/sd_y
covariance <- r * sd_x * sd_y
n <- 50
runs <- 500
sigma <-
matrix(
c(sd_x**2, covariance,
covariance, sd_y),
ncol = 2
)
pvalues <- NULL
for (i in 1:runs) {
d <- mvrnorm(
n,
means,
sigma
)
d <- as.data.frame(d)
pvalues[i] <- broom::glance(summary((lm(y ~ x, d))))$p.value
}
sum(pvalues < 0.05) / length(pvalues)[1] 0.778More than one cause
If we have more than one predictor, we need to specify effect sizes for each. Also, we need to be clear what our causal model is: We’re saying that both predictors are independently influencing our outcome. Otherwise we commit the Table II fallacy (Westreich and Greenland 2013). Simulating data also means simulating the causal structure.
What power?
If we want to simulate power for multiple predictors, powering for \(R^2\) is possible, but strange: It means powering for the total effect of all predictors. Just like with group differences, powering for a total effect can mean many underlying patterns:
- \(x_1\) explaining everything, but \(x_2\) and \(x_3\) explaining nothing
- \(x_1\) and \(x_2\) both explaining a moderate amount, but \(x_3\) explaining nothing
- All 3 explaining a little
- Etc.
What we need
Ideally, we power for all effectts meaning the smallest independent effect:
- Slope for each predictor
- Correlation between each predictor
- Correlation between each predictor and the outcome
- All means and SDs
How to simulate power for multiple causes? Next exercise.
Let’s do interactions
Categorical by continuous interactions
An interaction between a categorical and a continuous variable states that the effect of one depends on the other. Back to the linear model:
\[ y = \beta_0 + \beta_1x_1 + \beta_2x_2 + \beta_3x_1x_2 \]
In effect, we ask what information increasing both predictors adds to increasing them individually.
Example
Say we want to know the effect of framing of a message (positive vs. neutral) on how much people agree with it, but we expect the effect to depend on how much people like positive framing.
Pictures, plase
Therefore, we expect the effect to look something like this, if we were to plot means per group and liking:
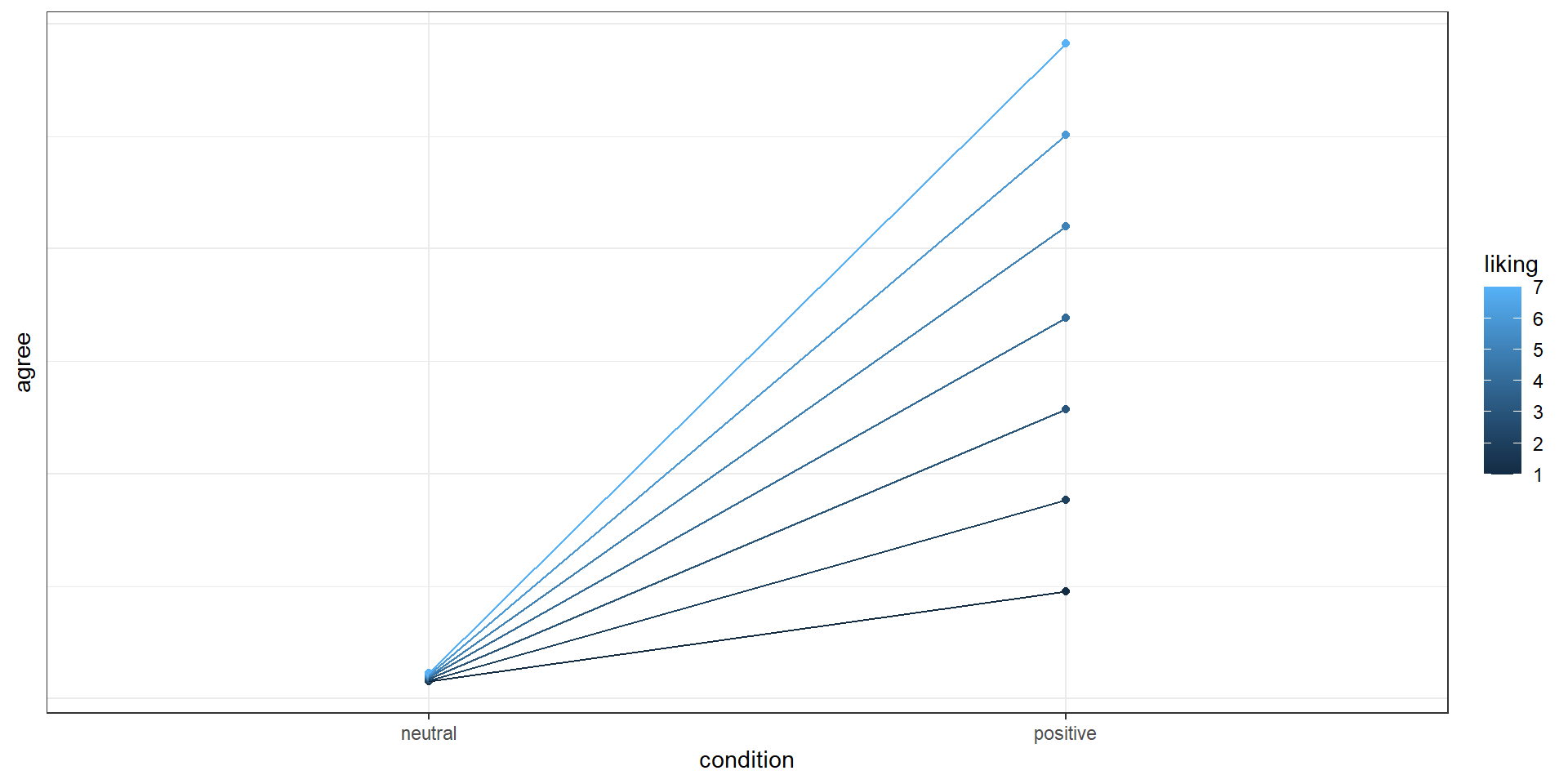
How to translate
\[ y = \beta_0 + \beta_1condition + \beta_2liking + \beta_3 \times condition \times liking \]
- \(\beta_0\): The outcome when condition is neutral and liking is 0
- \(\beta_1\): Difference between condition neutral and liking 0 and condition positive and liking 0 (aka main effect of condition)
- \(\beta_2\): Difference between condition neutral and liking 0 and condition neutral and liking 1 (aka main effect liking)
- \(\beta_3\): In addition to the condition effect, what does going up in liking by 1 add (or subtract) from the outcome?
Let’s create those scores
Let’s say we measure agreement on a 100-point scale. We make several assumptions:
- There’s probably no main effect of liking: Why would how much you like a positive message influence the effect of any message? It should only enhance the positive one.
- We’ll center liking: It makes it easier to think about what our coefficients mean.
- Let’s say at average liking (0 = centered), agreement is on the mid-point of the scale: 50
- We expect a positive message to “work” at average liking, so we put down a main effect of 5 points as our SESOI
- We expect that going up 1 point on liking will enhance our framing effect by 1 point
Put into numbers
\[\begin{align} & y = \beta_0 + \beta_1x_1 + \beta_2x_2 + \beta_3x_1x_2\\ & y = 50 + 5 \times condition + 0 \times liking + 1 \times condition \times liking \end{align}\]- \(\beta_0\): The outcome when condition is neutral and liking is 0 (i.e., average): 50
- \(\beta_1\): Difference between condition neutral and liking 0 and condition positive and liking 0 (aka main effect of condition): 5
- \(\beta_2\): Difference between condition neutral and liking 0 and condition neutral and liking 1 (aka main effect liking): 0
- \(\beta_3\): In addition to the condition effect, what does going up in liking by 1 add (or subtract) from the outcome?: 1
In R
set.seed(42)
b0 <- 50
b1 <- 5
b2 <- 0
b3 <- 1
n <- 1e4
error <- rnorm(n*2, 0, 20)
condition <- rep(0:1, n)
liking <- runif(n*2, min = 0, max = 7)
liking <- scale(liking, center = TRUE, scale = FALSE)
d <-
data.frame(
condition = condition,
liking = liking,
agree = b0 + b1 * condition + b2 * liking + b3 * condition * liking + error
)
d$condition <- as.factor(ifelse(d$condition == 0, "neutral", "positive"))
d$agree <- ifelse(d$agree > 100, 100, d$agree)
d$agree <- ifelse(d$agree < 0, 0, d$agree)Let’s find our numbers
Call:
lm(formula = agree ~ condition * liking, data = d)
Residuals:
Min 1Q Median 3Q Max
-57.891 -13.504 0.112 13.581 50.237
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 49.772322 0.198910 250.226 < 2e-16 ***
conditionpositive 5.177188 0.281301 18.404 < 2e-16 ***
liking 0.002632 0.097403 0.027 0.978
conditionpositive:liking 1.001518 0.138376 7.238 4.73e-13 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 19.89 on 19996 degrees of freedom
Multiple R-squared: 0.02175, Adjusted R-squared: 0.0216
F-statistic: 148.2 on 3 and 19996 DF, p-value: < 2.2e-16Pictures, please
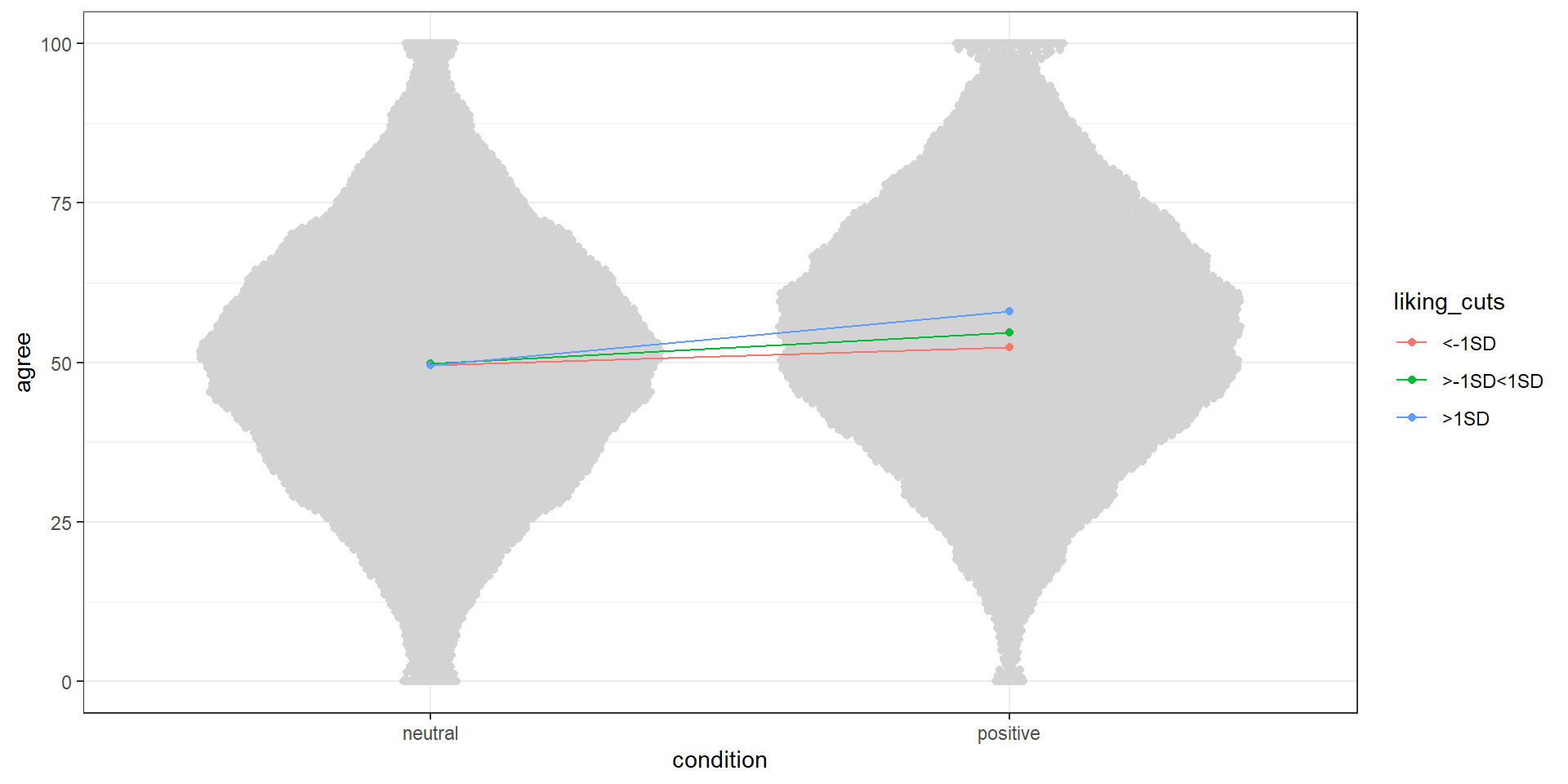
Two-way interaction
The interaction can also go way the other way around: The effect of A under B or the effect of B under A. In our case, we could also ask how the effect of liking a message is modified through framing. Same data, different plot:
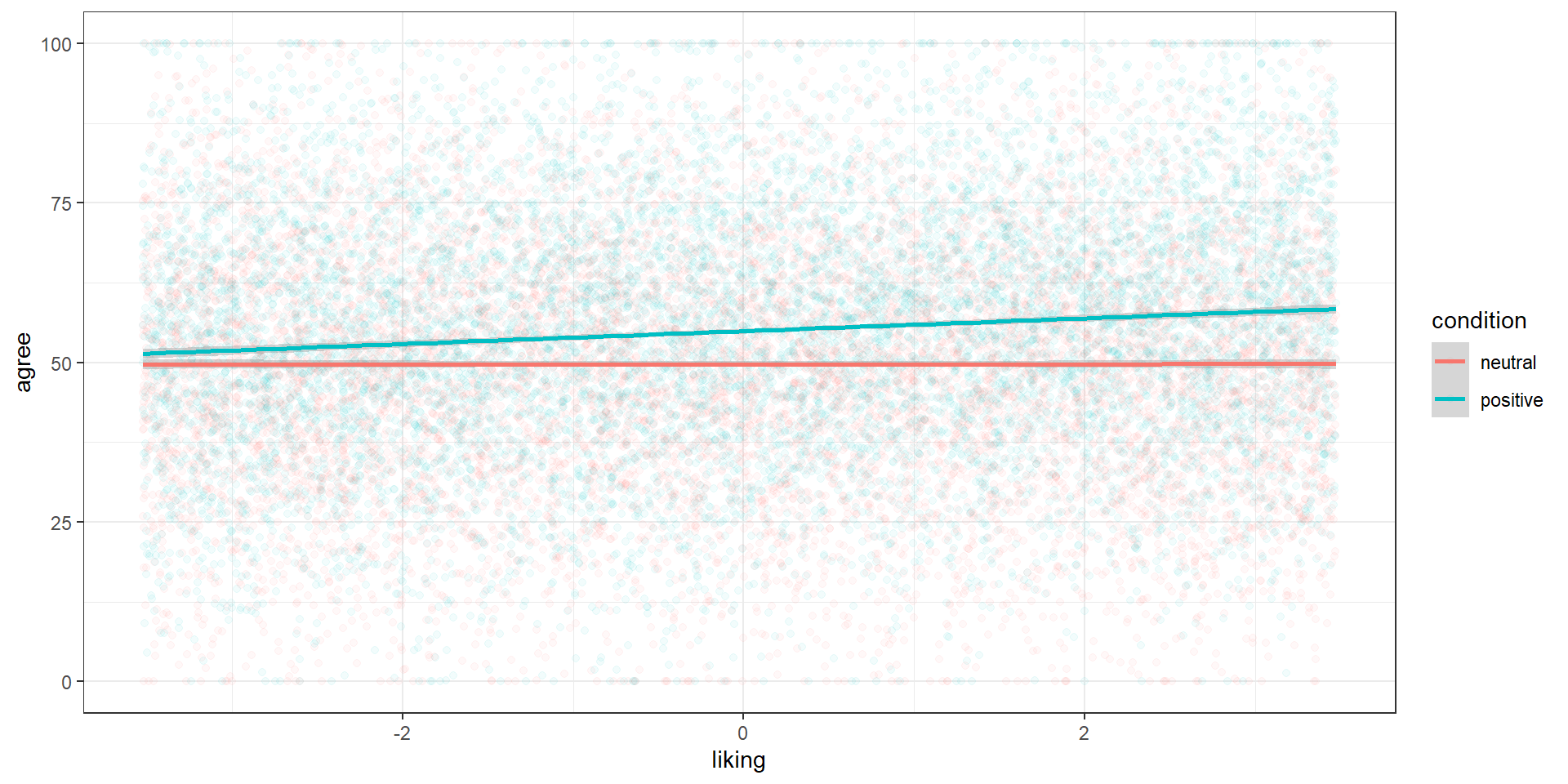
Let’s redo the logic
set.seed(42)
b0 <- 50
b1 <- 0 # no main effect of condition
b2 <- 2 # main effect of liking
b3 <- 3 # interaction
n <- 1e4
error <- rnorm(n*2, 0, 5)
condition <- rep(0:1, n)
liking <- runif(n*2, min = 0, max = 7)
liking <- scale(liking, center = TRUE, scale = FALSE)
d <-
data.frame(
condition = condition,
liking = liking,
agree = b0 + b1 * condition + b2 * liking + b3 * condition * liking + error
)
d$condition <- as.factor(ifelse(d$condition == 0, "neutral", "positive"))
d$agree <- ifelse(d$agree > 100, 100, d$agree)
d$agree <- ifelse(d$agree < 0, 0, d$agree)Now we’re looking at slopes
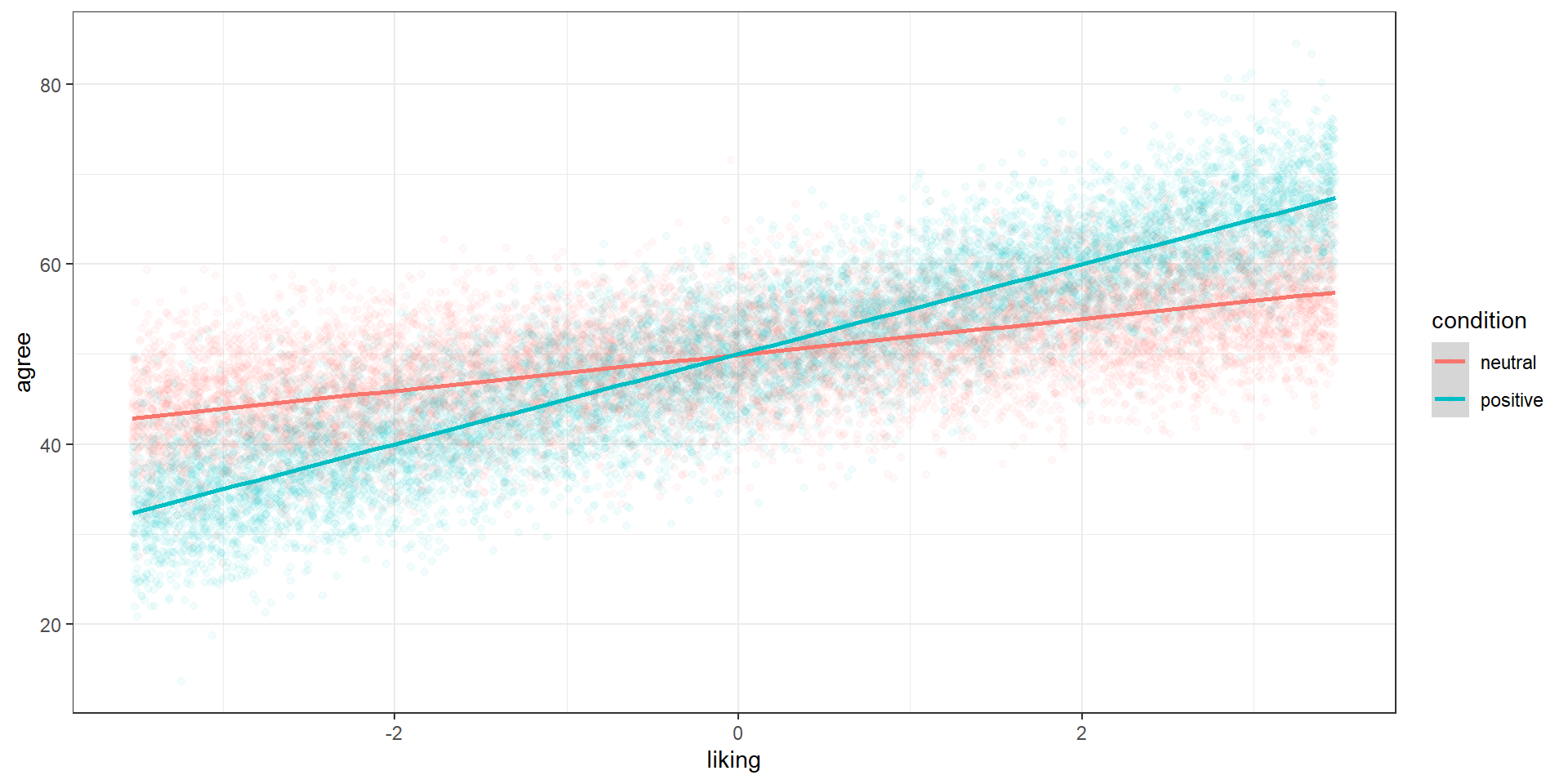
Continuous interactions
Same logic as before: What extra information do we gain if we go up on both variables compared to going up on them individually?
\(y = \beta_0 + \beta_1x_1 + \beta_2x_2 + \beta_3x_1x_2\)
Example
Say we want to know the effect of liking a message sender on agreeing with the sender’s message. However, we expect the effect to depend on how trustworthy the sender is.
Pictures, plase
We expect the effect to look something like this, if we were to plot a line per trustworthiness rating:
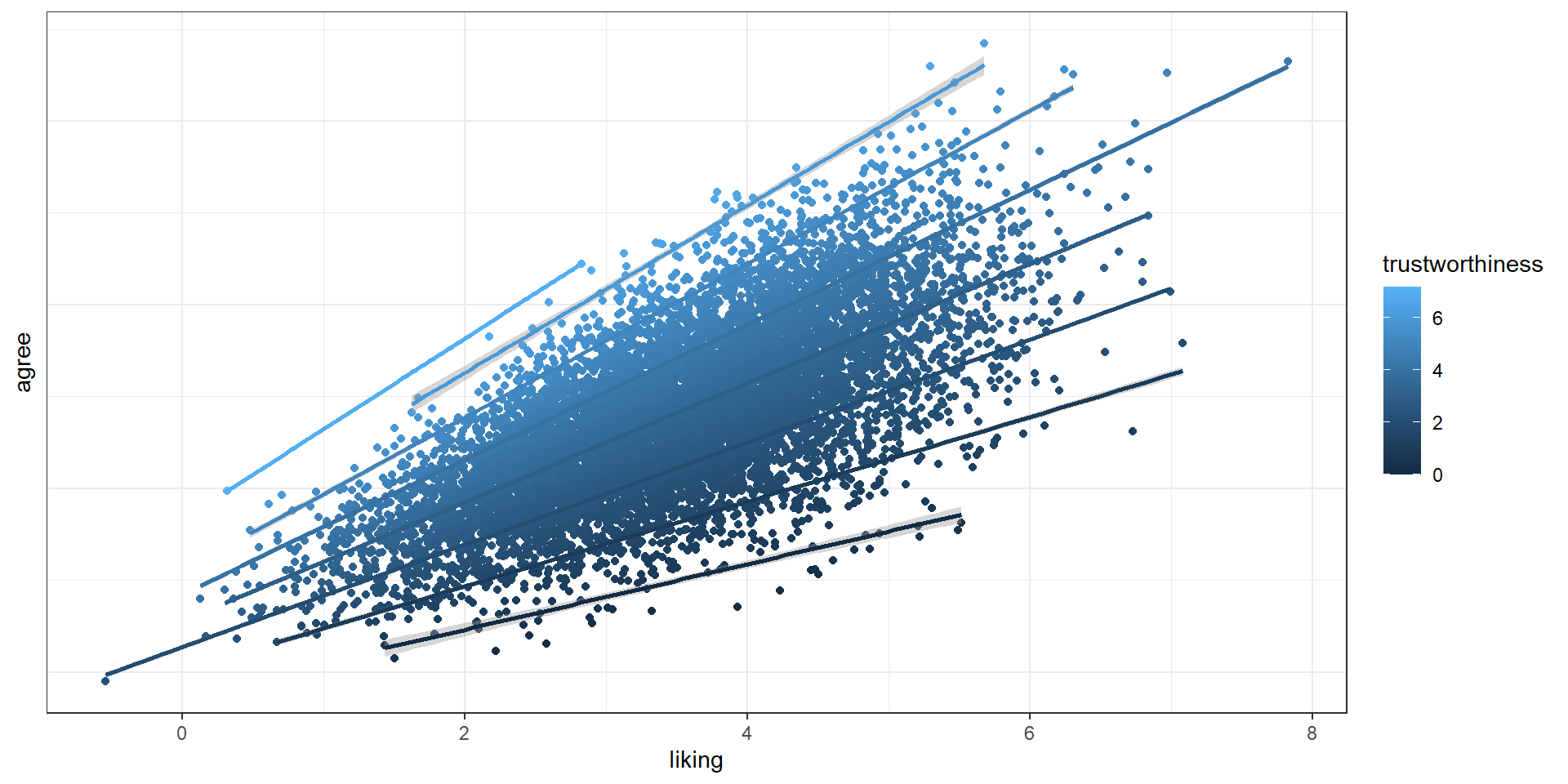
How to translate
\[ y = \beta_0 + \beta_1liking + \beta_2trust + \beta_3 \times liking \times trust \] Both predictors are centered, so 0 is their mean:
- \(\beta_0\): The outcome when both liking and trustworthiness are 0 (at their means)
- \(\beta_1\): Outcome when liking goes 1 up, but trustworthiness remains at average (= 0) (aka main effect of liking)
- \(\beta_2\): Outcome when trustworthiness goes 1 up, but liking remains at average (= 0) (aka the main effect of trustworthiness)
- \(\beta_3\): In addition to the effect of liking going up 1, what does going up in trustworthiness by 1 add (or subtract) from the outcome?
Let’s create those scores
Once more, we measure agreement on a 100-point scale. We make several assumptions:
- We’ll center both predictors: It makes it easier to think about the interaction.
- At average liking and trustworthiness (0 = centered), agreement is on the mid-point of the scale: 50
- There’s a main effect of liking: With each extra point (at average trustworthiness), agreement should go up by 3 points.
- There’s a main effect of trustworthiness: With each extra point (at average liking), agreement should go up by 2 points.
- We expect that going up on trustworthiness will enhance our liking effect by 2 points
Put into numbers
\[\begin{align} & y = \beta_0 + \beta_1x_1 + \beta_2x_2 + \beta_3x_1x_2\\ & y = 50 + 3 \times liking + 2 \times trust + 2 \times liking \times trust \end{align}\]- \(\beta_0\): The outcome when both liking and trustworthiness are 0: 50
- \(\beta_1\): Outcome when liking goes 1 up, but trustworthiness remains at average: +3
- \(\beta_2\): Outcome when trustworthiness goes 1 up, but liking remains at average: +2
- \(\beta_3\): In addition to the effect of liking going up 1, also going up in trustworthiness 1 adds to the outcome: 2
In R
set.seed(42)
b0 <- 50
b1 <- 3
b2 <- 2
b3 <- 2
n <- 1e4
error <- rnorm(n, 0, 20)
liking <- runif(n, 0, 7)
trustworthiness <- runif(n, 0, 7)
liking <- scale(liking, center = TRUE, scale = FALSE)
trustworthiness <- scale(trustworthiness, center = TRUE, scale = FALSE)
d <-
data.frame(
liking = liking,
trustworthiness = trustworthiness,
agree = b0 + b1 * liking + b2 * trustworthiness + b3 * liking * trustworthiness + error
)
d$agree <- ifelse(d$agree > 100, 100, d$agree)
d$agree <- ifelse(d$agree < 0, 0, d$agree)Let’s find our numbers
Call:
lm(formula = agree ~ liking * trustworthiness, data = d)
Residuals:
Min 1Q Median 3Q Max
-59.451 -13.609 0.126 13.583 66.108
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 49.68043 0.19581 253.72 <2e-16 ***
liking 2.97717 0.09649 30.85 <2e-16 ***
trustworthiness 1.83232 0.09605 19.08 <2e-16 ***
liking:trustworthiness 1.92430 0.04730 40.69 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 19.58 on 9996 degrees of freedom
Multiple R-squared: 0.2276, Adjusted R-squared: 0.2274
F-statistic: 982 on 3 and 9996 DF, p-value: < 2.2e-16Pictures, plesase
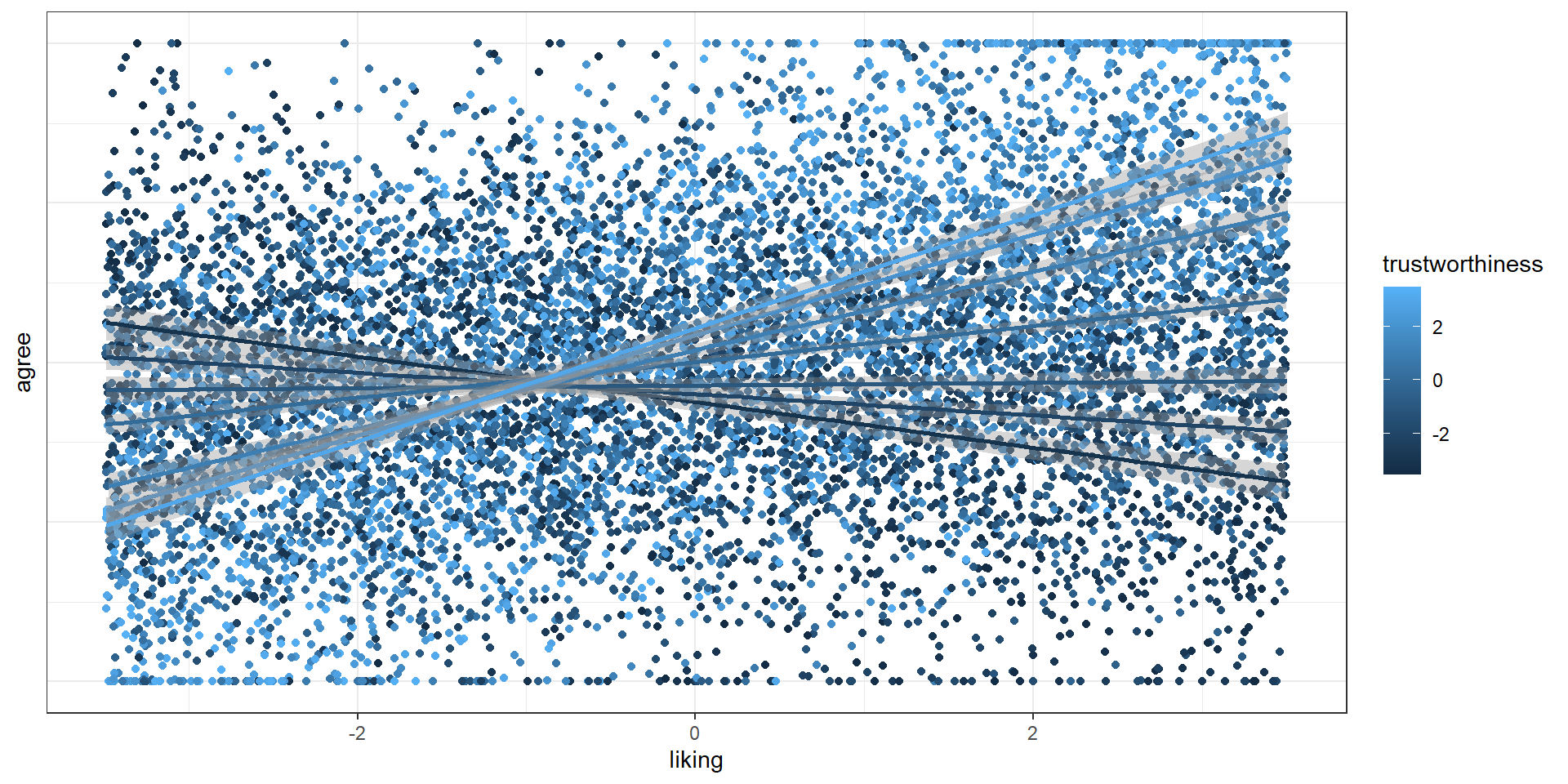
Interaction plots
In the above plot, I cheated a bit by rounding trustworthiness so that we can get only 7 “levels”. With truly continuous variables, we usually operate with standard deviations: What’s the effect of liking on agreeing when trustworthiness is 1 SD above or below its mean? You can create those plots yourself or rely on other packages.
Prediction plots
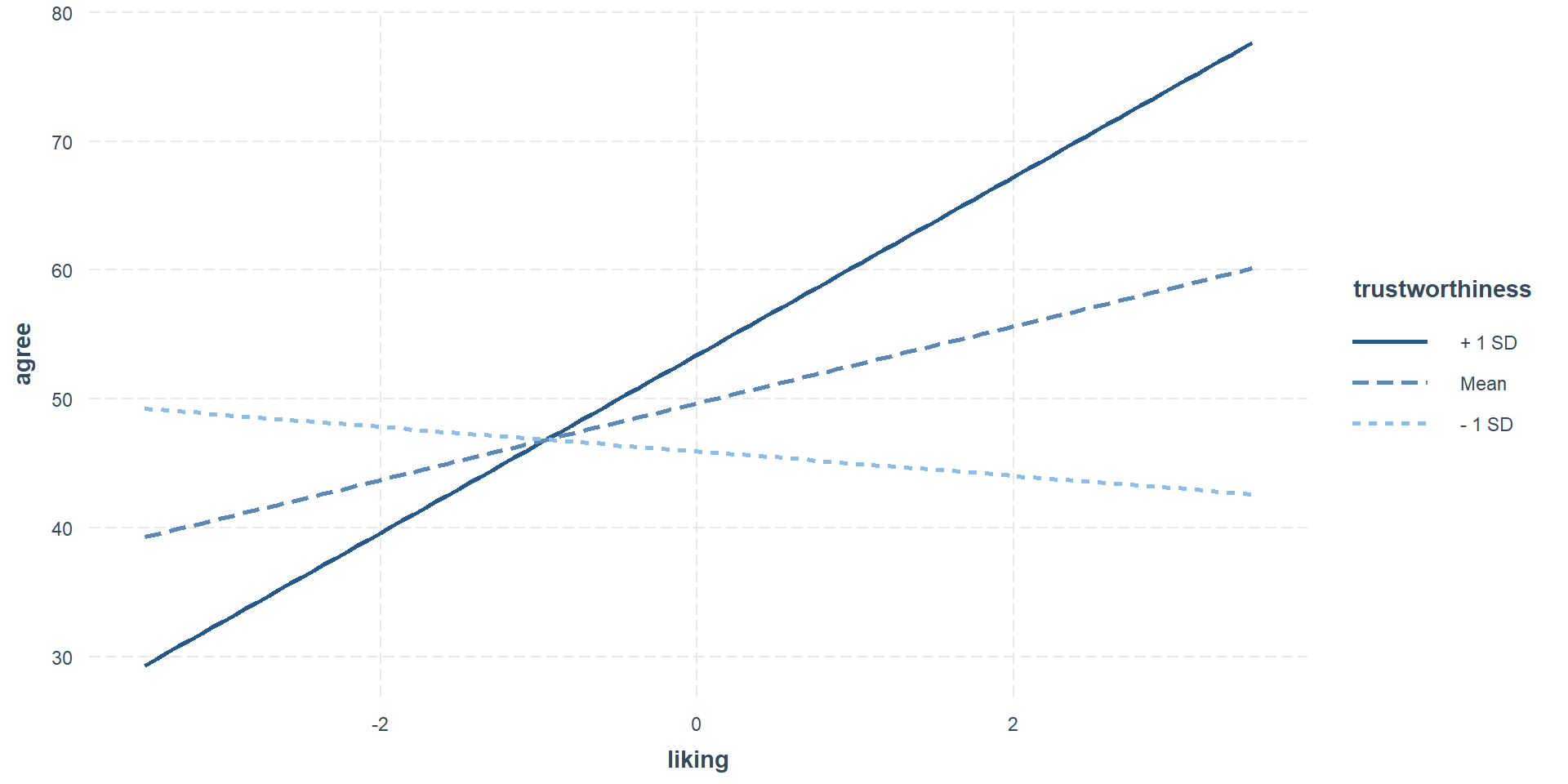
From the matrix
\(y = \beta_0 + \beta_1x_1 + \beta_2x_2 + \beta_3x_1x_2\)
The interaction term is really just a product, so we can treat it as its own variable. We can simply create a correlation matrix where we specify how the product of two variables (aka \(x_1 \times x_2\)) should correlate with our outcome.
\[ \begin{bmatrix} & x_1 & x_2 & x_1x_2 & y \\ x_1 & 1 & & & \\ x_2 & r & 1 & &\\ x_1x_2 & r & r & 1 &\\ y & r & r& r& 1 \end{bmatrix} \]
Putting that into numbers
Let’s say liking is correlated to agreeing with 0.2, trustworthiness with 0.25, and the interaction “adds” 0.1 standard deviations. The interaction is correlated to liking and trustworthiness with 0. Liking and trustworthiness are correlated at 0.4.
\[ \begin{bmatrix} & x_1 & x_2 & x_1x_2 & y \\ x_1 & 1 & & & \\ x_2 & 0.4 & 1 & &\\ x_1x_2 & 0 & 0 & 1 &\\ y & 0.2 & 0.25 & 0.1 & 1 \end{bmatrix} \]
In R
Let’s find our numbers
Summary
Remember: Those are conditional effects, not just 1-to-1 correlations.
Call:
lm(formula = y ~ x1 + x2 + x1x2, data = d)
Residuals:
Min 1Q Median 3Q Max
-3.3061 -0.6368 0.0043 0.6319 3.4221
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.006035 0.009414 0.641 0.521
x1 0.120853 0.010219 11.826 <2e-16 ***
x2 0.196707 0.010297 19.103 <2e-16 ***
x1x2 0.106056 0.009338 11.358 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.9414 on 9996 degrees of freedom
Multiple R-squared: 0.08888, Adjusted R-squared: 0.0886
F-statistic: 325 on 3 and 9996 DF, p-value: < 2.2e-16What about raw?
If we want to work on the raw scale, we once more need the standard deviations. We could do the transformation per variable variable pairing, but that gets very unwieldy. At this point, you’d need to do some matrix multiplication, see here for a starter.
Takeaways
- Understand that continuous predictors are just another case of the linear model
- Extend this understanding to continuous (by categorical) interactions
- Be able to translate that extension to generating data
References
Westreich, Daniel, and Sander Greenland. 2013. “The Table 2 Fallacy: Presenting and Interpreting Confounder and Modifier Coefficients.” American Journal of Epidemiology 177 (4): 292–98. https://doi.org/10.1093/aje/kws412.
Wysocki, Anna C., Katherine M. Lawson, and Mijke Rhemtulla. 2022. “Statistical Control Requires Causal Justification.” Advances in Methods and Practices in Psychological Science 5 (2): 25152459221095823. https://doi.org/10.1177/25152459221095823.